Export FastAI ResNet models to ONNX
#fastai #onnx #pytorch #machinelearning #computervision

A short guide on FastAI vision model conversion to ONNX. Code included. 👀
What is FastAI?
FastAI is "making neural nets uncool again". It offers a high-level API to PyTorch. It could be considered the Keras of PyTorch (?). FastAI and the accompanying course taught by Jeremy Howard and Rachel Thomas has a practical approach to deep learning. It encourages students to train DL models from the first minute. BUT I am sure you already have hands-on experience with this framework if you are looking to convert your FastAI models to ONNX.
What is ONNX?
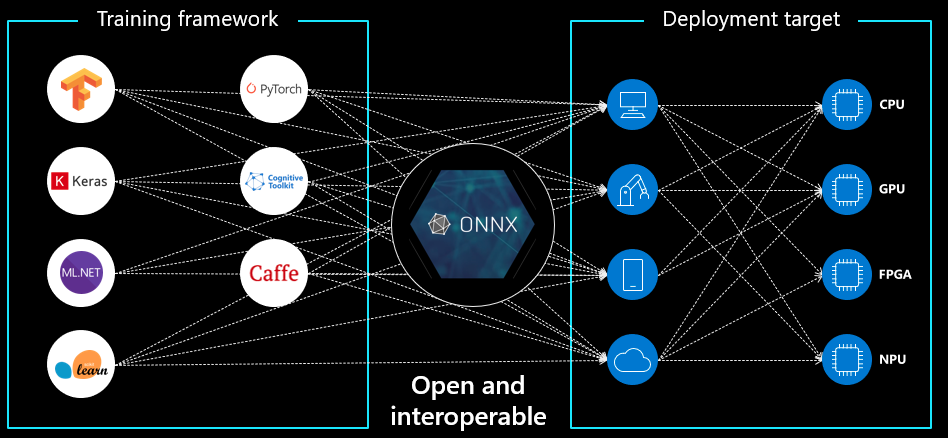
Open Neural Network Exchange or ONNX is a unified format for deep learning and traditional machine learning models. The idea behind ONNX is to create a common interface for all ML frameworks and increase the interoperability between frameworks and devices.
ONNX is an open specification that consists of a definition of an extensible computation graph model, definition of standard data types, and definition of built-in operators. Extensible computation graph and definition of standard data types make up the Intermediate Representation (IR).
Source [link]
Source [link]
ONNX, and its implementation - ONNX Runtime, make it easier to put your models into production. You can train your models using the framework of your choice and deploy to a target that uses ONNX Runtime. This way bloated environments with large number of dependencies can be minimized to (pretty much) only ONNX Runtime. There's a growing support to ONNX, and exports are being natively supported by frameworks like PyTorch, MxNet, etc. Find all of them here [link]. Although in some cases it might be tricky to export/import, due opset compatibility.
Why use ONNX and ONNX Runtime?
Couple of reasons here:
- Faster inference [link], [link]
- Lower number of dependencies*
- Smaller environment size*
- One, universal target framework for deployment
*See conda environment and dependency comparison at the end of the article.
The Process
FastAI currently doesn't natively support ONNX exports from FastAI learners. But by design FastAI is a high-level API of PyTorch. This allows us to extract the wrapped PyTorch model. And luckily, PyTorch models can be natively exported to ONNX. It's a 2-step process with a couple of gotchas. This guide intends to make it a smooth experience.

You can find the entire process in my repository [link]. It also includes an optional ResNet model training. You can skip it and proceed with model export to ONNX. I included a link to a pre-trained model in the notebooks. Or BYOFM - Bring Your Own FastAI Model.
Export (Extract) the PyTorch model

Let's break down what's happening.
If you check the associated notebooks you will find that I exported the FastAI ResNet learner in the previous steps. And named it hot_dog_model_resnet18_256_256.pkl. With load_learner() I am loading the previously exported FastAI model on line 7. If you trained your own model you can skip the load step. Your model is already stored in learn.
To get the PyTorch model from the FastAI wrapper we use model attribute on learn - see line 12. I don't want to train the model in subsequent steps thus I am also setting it to evaluation mode with eval(). For more details on eval() and torch.no_grad() see the discussion [link].
FastAI wraps the PyTorch model with additional layer for convenience - Softmax, Normalization, and other transformation(defined in FastAI DataBlock API). When using the bare-bones PyTorch model I have to make up for this. Otherwise I'll be getting weird results.
First, I define the softmax layer. This will turn inference results into more human readable format. It turn the inference results from something likes this ('not_hot_dog', array([[-3.0275817, 1.2424631]], dtype=float32)) into ('not_hot_dog', array([[0.01378838, 0.98621166]], dtype=float32)). Notice the range of inference results - with the added softmax layer the results are scaled between 0-1.
On line 18, the normalization layer is defined. I am reusing the suggested ImageNet mean and standard deviation values as described here [link]. If you are interested in an in-depth conversation on the topic of normalization. See this [link].
On lines 21-25, I am pulling all together into the final model. This final model will be used for ONNX conversion. FastAI learner also handles resizing but for PyTorch and ONNX this will be handled outside of the model by an extra function.
Export PyTorch to ONNX

PyTorch natively support ONNX exports, I only need to define the export parameters. As you can see we are (re)using the final_model for export. On line 5 I am creating a dummy tensor that is used to define the input dimensions of my ONNX model. These dimensions are defined as batch x channels x height x width - BCHW format. My FastAI model was trained on images with 256 x 256 dimension which was defined in our FastAI DataBlock API. The same dimensions must be used for the ONNX export - torch.randn(1, 3, 256, 256).
I got this wrong a couple of times - the dummy tensor had different dimensions than the images the model was trained on. Example: Dummy tensor torch.randn(1, 3, 320, 320) while training image dimensions were 3 x 224 x 224. It took me a while to figure out why I got poor results from my ONNX models.
The export_param argument, if set to True, includes the parameters of the trained model in the export. It's important to use True in this case. We want our model with parameters. As you might have guessed, export_params=False exports a model without parameters. Full torch.onnx documentation [link].
Inference with ONNX Runtime

On line 10, I am creating an ONNX runtime inference session and loading the exported model. For debugging purposes, or if you get your hands on an ONNX model with unknown input dimensions. You can run get_inputs()[0].shape on the inference session instance to get the expected inputs. If you prefer a GUI, Netron [link] can help you to visualize the architecture of the neural networks.
The inference itself is done by using the run() method which returns a numpy array with softmaxed probabilities. See line 21.
Storage, Dependencies & Inference Speed
Storage
The advantage of using ONNX Runtime is the small storage footprint compared to PyTorch and FastAI. A conda environment with ONNX Runtime (+ Pillow for convenience) is ~ 25% of the PyTorch environment and only ~ 15% of the FastAI environment. Important for serverless deployments.
Dependencies
See for yourself.
Inference speed
I mentioned inference speed as an advantage of ONNX. I tested the inference speed of all three versions of the same model. There were negligible differences between inference speed. Other experiments had more favourable results for ONNX. See references in Why use ONNX and ONNX Runtime?
Summary
FastAI is a great tool to get you up and running with model training in a (VERY) short time. It has everything you need to get top notch results with minimal effort in a practical manner. But when it comes to deployment, tools like ONNX & ONNX Runtime can save resource with their smaller footprint and efficient implementation. Hope this guide was helpful and that you managed successfully convert your model to ONNX.
Repository/Code
Feel free to reach out.👏
> > > >