TinyML: Machine Learning on ESP32 with MicroPython
#tinyml #micropython #esp32 #timeseries #machinelearning #gesturedetection
Detecting gestures from time-series data with ESP32, accelerometer, and MicroPython in near real-time.
Why this project?
I wanted to build a TinyML application that uses time-series data and could be deployed to edge devices - ESP32 microcontroller in this case. I looked into machine learning projects that use MicroPython on ESP32 but could not find any (let me know if I am missing something 🙃). Although, There's a growing number of C/C++ TinyML projects using Tensorflow Lite Micro in combination with neural networks. For the first iteration of this project I skipped neural networks and explored what's possible with standard machine learning algorithms.
Before jumping into code, let's clear the basics...
Introducing TinyML
What's TinyML?
TinyML is the overlap between Machine Learning and embedded (IoT) devices. It gives more "intelligence" to power advanced applications using machine. The idea is simple - for complex use-cases where rule-based logic is insufficient; apply ML algorithms. And run them on low-power device at the edge. Sounds simple; execution gets tougher.

TinyML is a fairly new concept, first mentions are dating back to 2018(?). There's still ambiguity about what is considered TinyML. For the purpose of this article, TinyML applications are applications running on microcontrollers with MHz of clock speed up to more powerful ones like the Nvidia Jetson Family. Raspberry included. Other names for TinyML are AIoT, Edge Analytics, Edge AI, far-edge computing. Choose the one you like the most.
Why TinyML?

- Bandwidth - As an example, a device at 100Hz sampling rate produces 360,000 data points each hour. Now imagine the amount of data produced by a fleet of these devices. It get's even trickier with images and video.
- Latency - "time between when a system takes in a sensory input and responds to it". In case of conventional ML deployment data must be first sent to an ML application. This increases the time in which an edge device can take action as it waits for the response.
- Economics - Cloud is cheap but not so cheap. It still costs money to ingest large amounts of data, especially if it must happen in real-time.
- Reliability - Revisiting the bandwidth example, in case of high-frequency sampling, it might be hard to ensure that data arrives to a target in the same order as it was produced by an edge device.
- Privacy - TinyML processes data on-device and is not sent through network. This reduces the surface for data abuse.
TinyML use cases
TinyML use cases can range from predictive maintenance all the way to virtual assistants. I might write an article on the current landscape, use cases, and business behind case behind TinyML.
What's this TinyML Project about?
I set out to build a TinyML system that detects 3 types of gestures (I will be using gestures/movements interchangeably throughout this article.) from a time-series, stores results, and visualizes them on a webpage.
The system has a static webpage hosted on S3 buckets, DynamoDB, a Golang Microservices, and obviously the edge device with a TinyML application.
Project architecture

While there are more components to this project. This article will be about machine learning and some parts of the implementation on ESP32. If you are interested in the full code you can find the links to the repositories at the end of this article.
Let's go to the edge and see the hardware.
On the edge

The core of the system is an ESP32 - a microcontroller produced by Espressif with 240MHz clock speed, built-in WiFi+BLE and ability to handle MicroPython🐍 (I used MicroPython 1.14). The IMU used for this project was an MPU6500 with 6 degrees of freedom (DoF) - 3 accelerometers (X,Y,Z) and 3 angular velocities (X,Y,Z). Plus breadboard and jumper wires to connect it all together.
MicroPython
If you haven't yet heard about MicroPython - it's Python for microcontrollers.
"MicroPython is a lean and efficient implementation of the Python 3 programming language that includes a small subset of the Python standard library and is optimized to run on microcontrollers and in constrained environments." [Link]
It's might not be as performant as C or C++ but provides plenty to make prototyping enjoyable. Especially for IoT applications which are not latency sensitive. (*It worked fine with 100Hz sampling rate)
Data & Machine Learning
Gestures definition
You can find the 3 gestures for which I collected data below. I call them 'circle', 'X' and 'Y' - gifs follow the same order. 'Circle' is self-explanatory. 'X' and 'Y' because to gesture was along the X and Y axis of the sensor, respectively. Ideally, I would have wanted to detect anomalies on real machine data but that type of data is hard to come by and also hard to replicate. My defined gestures, on the other hand, were easy to generate and more than enough to test the possibilities of MicroPython and ESP32.

Experiments
Experimentation with Machine learning was divided into two parts - the first explored the effects of time-series labelling on model performance. I use all available signals from the sensors - X,Y,Z accelerations and X,Y,Z angular velocities. Additionally, I tested the viability of ML on ESP32 from the inference time perspective. Whether, it will be possible to achieve low enough inference times.
The focus of the second set of experiments was model optimization, reducing feature space, selecting the right sampling frequency, and reducing incorrect inference results.
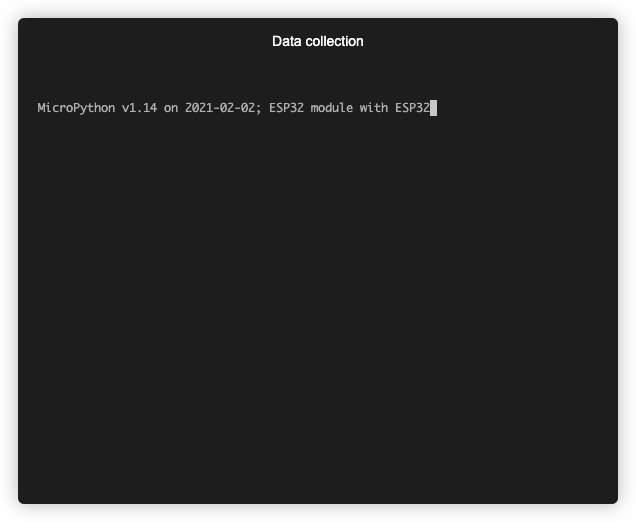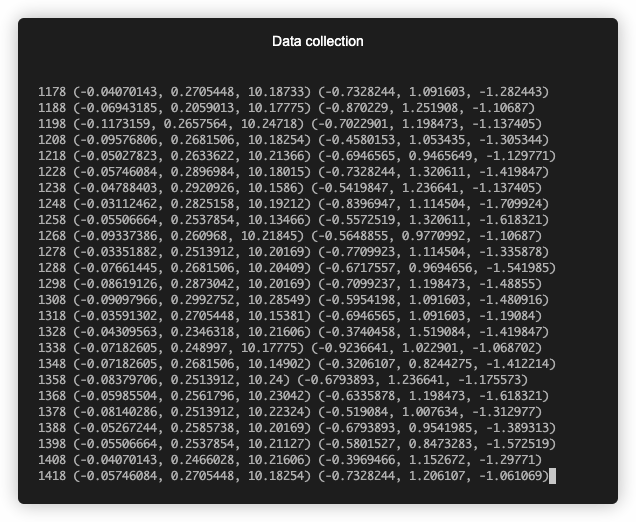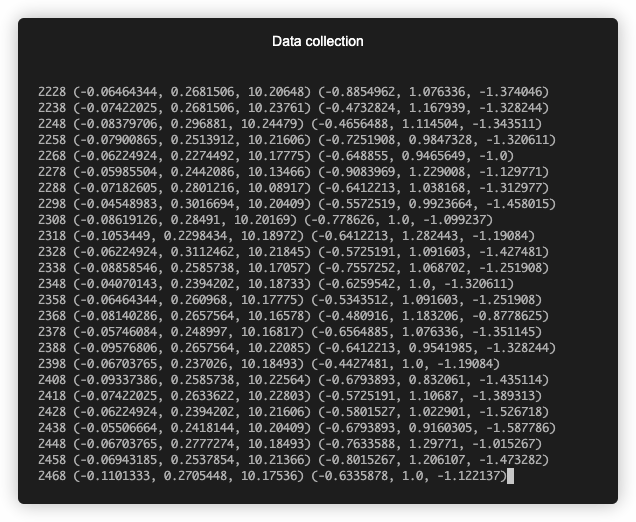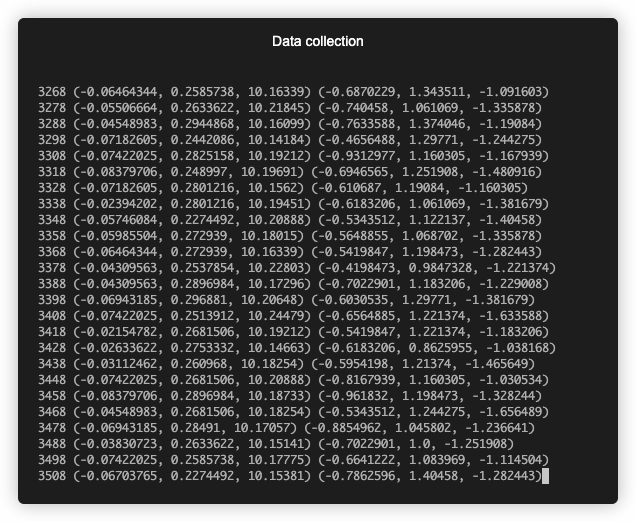
Collecting data
I simplified data collection by using Terminal Capture VS Code extension. It let me save sensor data from VSC's terminal to a txt file which I later wrangled to csv format. For printing out sensor data I wrote the below script. It runs on ESP32 at startup with a 10ms sampling period (100Hz sampling rate). 10ms was the lowest I could get with consistent results. I tried a period=5 but the readings were inconsistent with readings between 5-7ms. Hitting the first limitation of the stack. Nonetheless, 10ms (100Hz) was more than enough.
And this is how it works:
Labelling and label distribution
There are great labelling tools out there, I used labelstud.io to label my time-series data. Among the 3 defined gestures 'circle' is the longest, at around 800-1000ms, 'X', and 'Y' are between 400-600ms. To have a buffer, I used a 1000ms label span for all three of the labels.

Exploring the dataset - EDA
I used 3D plots to see if there's a relationship between the signals. All data points of the 1000ms time span are plotted (101 data points).
Acceleration 3D plot

Angular velocity 3D plot

It's clear that there's a pattern in gesture accelerations and angular velocities.
Let's double check by plotting all signals against their mean. You can find plots of all gestures and correlation matrices in jupyter notebooks in the associated repository.

Note: The cutoff at the top and bottom of the signals is due sensor range which was set to 2G (~19.6 m/s^2).
Machine Learning to detect gestures
Since ESP32, and microcontrollers in general, are resource constrained there's a couple of requirements for my TinyML application:
- Inference time << sampling period
- ML model < 20kB - it's hard do load files larger than 20kB onto ESP32 (at least with MPY)
MicroPython is still a young project, supported by an active community and there are many libraries already developed. Unfortunately there's no scikit-learn or a dedicated time-series machine learning library for MicroPython.
How to overcome this?
The answer is pure-python machine learning models. Luckily, I found a great library (m2cgen) that let's you export scikit-learn models to Python, Go, Java (and many other) programming languages. It doesn't have time-series specific ML model export capabilities. So, I'll be using standard scikit-learn algorithms.

In practice it looks like this:
- Train models with scikit-learn on tabular data
- Convert scikit-learn models to pure-python code
- Use pure-python models for inference
Caveats of using scikit-learn for time-series data
Using scikit-learn for time-series comes with a price - data must be in a tabular format to train the models. There are two ways to go about this [link]:
Tabularizing(reducing) data
In this case each time point is considered a feature and we lose order of data in time. There's no dependency of one point on the previous or next in the series.
Feature extraction
In case of feature extraction time-series data is used to calculate mean, max, min, variance and other, time-series specific, variables which are then used as features for model training. We moved away from the time-series domain and operate in the domain of features.
I chose data tabularization. While it's simple to call advanced libraries in Python - MicroPython has a limited mathematical toolset - I might not be able extract all features in MPY. Secondly, I had to consider the speed at which these features could be calculated - given the limited resources might take longer than sampling period. Maybe in the next iteration of this TinyML project.

Dataset variations for ML model training
Event position in label
This affected 'X' and 'Y' gestures since their execution takes between 400-600ms. It was possible to change their position in the 1000ms label window. 'Circle' takes 800-1000ms so I left this gesture as labelled.

Dataset description
Baseline dataset
Dataset used for training and validation contained movements as collected and labeled.
Centered X and Y move signals
'Circle' movement takes up the whole span of 1000ms and cannot be manipulated by moving it along the time axis. However 'X' and 'Y' have shorter execution at around 400-600ms and allow for flexibility. I tried to center the movement of the signal in the center of the 1000ms window to see if the model will perform better with this setup.
Centered X and Y move signals + Augmentation
Similarly as in previous case 'X' and 'Y' movements were in the center of the 1000ms window. Additionally, a sort of augmentation was introduced. Since labelling the movements is not 'exact' some signals might have a misaligned start. To make up for this, and possibly achieve a better generalization I added a shift - meaning I used a range of small shifts.
For 'X' and 'Y' movements the center is at -20 steps . For augmentation a range between -20 and -15 was used. Where one step is 10ms.
For 'circle' a range between -2 and 2 was used.
Example: If the original label starts at 0 and the augmented dataset was shifted by -1 step - the augmented dataset will have its start at 0-10ms step.
Centered X and Y move signals + SMOTE
Simlarly, as previous two cases 'X' and 'Y' are centerd but additional synthetic oversampling is used (SMOTE) and an equal amount of labels is create for the training dataset.
X and Y signal at the end of the window
In this case the 'X' and 'Y' movements are put at the end of the 1000ms sampling window.
Data sampling rate Data was collected at 100Hz which allowed me to downsample. You can find the frequencies used for model training below.

Model evaluation
After the initial model training, deployment and inference on live data I noticed that inference on ESP32 was too sensitive - multiple detections for the same movement occurrence. I collected a validation dataset to see what happens when used with live data. Each validations dataset - 'circle', 'X', 'Y' contained 5-6 gesture events.
I emulated live data feed through a sliding inference window, which makes an inference at each step while it's sliding through the time-series. Each green(circle), blue(X), and red(Y) represent one inference. These line are in the center of the sliding window (i.e. T + 500ms).
See the example below - all of these models had 0.95+ accuracy but still produce incorrect inference results when emulating live data on validation datasets.

Evaluation equation I used the below equations to do so. For each dataset I calculated the ratio of incorrect labels that shouldn't be there. I acknowledge that I should have labelled my evaluation datasets but I needed a quick way to quantitatively evaluate models.
| Label | Equation |
| Cirle | cirle_error = X+Y / (X+Y+Circle) |
| X | x_error = Circle+Y / (X+Y+Circle) |
| Y | y_error = Circle+X / (X+Y+Circle) |
Baseline model training results
Initially I used 5 models for baseline model training but reduced it to Decision Trees and Random Forests from the initial set of Decision Tree, Random Forest, Support Vector Machines, Logistic Regression, and Naive Bayes. m2cgen doesn't support Naive Bayes so I was unable convert NB models to pure-python. Logistic Regression and SVMs had issues with inference times when converted to pure-python.
Both Random Forests and Decision Tree settings were left on default.

As you can see there's nothing conclusive with regards to sampling frequency and event position in the label. On top of that, I noticed large variations in results just by changing the random_seed of the model. I assume this could be solved by collecting more data.
You can see the results of means across all 3 movement errors can be found below. Again there's no clear winner so going forward I will be using the baseline dataset to train optimized models - sticking to the basics.

Testing inference time

I tested inference times of Random Forests with different number of estimators to see what's the highest number that is still usable. Inference time with 10 estimators is approximately 4ms which is viable even at 10 ms sampling period. Additionally, the ESP32 was set to 160MHz clock speed, for the actual script I will be using 240MHz (50% increase) which will further decrease inference times.
Note: Random Forests are just ensembles of Decision Trees - if Random Forest pass Decision Trees will pass as well.
Optimizing models
I tested inference times of Random Forests with different number of estimators to see what's the highest number that is still usable. Inference time with 10 estimators is approximately 4ms which is viable even at 10 ms sampling period. Additionally, the ESP32 was set to 160MHz clock speed, for the actual script I will be using 240MHz (50% increase) which will further decrease inference times.
Note: Random Forests are just ensembles of Decision Trees - if Random Forest pass Decision Trees will pass as well.
Considered optimization
Optimizing the number of estimators
Number of estimators must be kept low - ideally between 3-5 because of time constraints.
Optimizing the number of collected inputs
X,Y,Z acceleration signals must be collected for a different part of the application. I considered to create a combination of acceleration and 1 or 2 angular velocity signals.
Optimizing sampling rate
Sampling rate of 100Hz might be an overkill for the application. And based on evaluation results it doesn't offer any benefit over 50Hz or 20Hz sampling rate. On the other hand 10Hz might be too slow. Therefore for experiments I will be using 20, 25 and 50Hz sampling rates.
To train optimized models I used a grid search over the parameters below.

Comparing the results
In the charts you can see the results for all 3 gestures. Blue dots and line represent the baseline model (not optimized model) and red dots and line optimized models (result of grid search). Horizontal lines in each of the charts are the means of all 3 gestures.

The best model is ID #2.
Comparing model #2 to baseline model
Baseline model was trained with all 6 signals at 50Hz with default settings. It's counter intuitive but by reducing the number of signals it was possible to reduce the number of incorrect inferences. Same evaluation methods were used as described in previously.

Although the inference improved by reducing the number of signals and tuning the hyperparameters - it's far from perfect. There are two phenomenons in the inference results - first there are groups of same CORRECT inferences and secondly there's a trailing inference (mostly for circle gestures). The trailing inferences are due residual movement at the end of the circle motion. While these might be correctly classified, they are unwanted and must be filtered out. Ideally, there's only one correct inference per event that is sent to the REST API.

Debouncing inference results
I am assuming models have a window around the 'true' center of movement. Meaning, models will make inference few ms before and after the 'true' movement point. Additionally, there are incorrect 'trailing' inferences.

My debounce implementation is based on two conditions. One of them compares the time difference between the first and last inference in an inference buffer('Circle', 'X', and 'Y' inference results are added to the inference buffer.). The other one evaluates the number of inferences in the inference buffer.
For the window around the 'true' movement I am assuming 200ms which practically allows 9 inferences at 50Hz sampling rate. Therefore, the inference buffer must contain at least 9 values.
The time difference threshold value is set to 450 ms. After experimentation it worked the best at 50Hz sampling rate. It filtered out trailing inferences of 'Circle' gesture while still detecting 'X' and 'Y' gestures. Values above 450ms were unable to detect them. In contrary, time difference threshold values below 400ms were classifying 'trailing' inferences as separate gestures (often of incorrect type)
If above conditions are met - the most frequent value of the first 9 elements in the inference buffer are returned as the final inference result.
Note: This is still wip and I am thinking about smarter re-implementations.
Debouncing implementation
Comparing raw and debounced inference results
The results are cleaner but there's still room for improvement - there should be only in inference per event in 'Circle' eval data and all events should be picked up in 'X' and 'Y'.
Circle

X

Y

In general the results look better than those produced by baseline models.
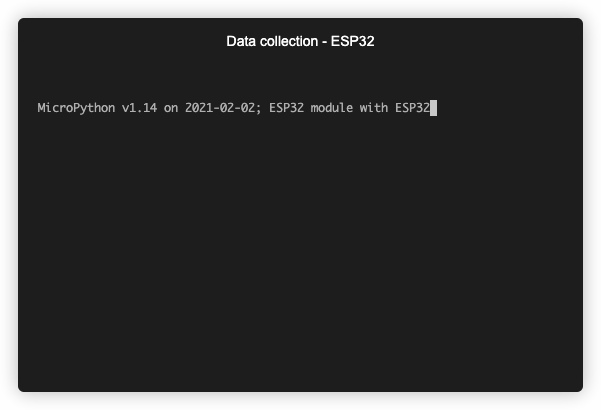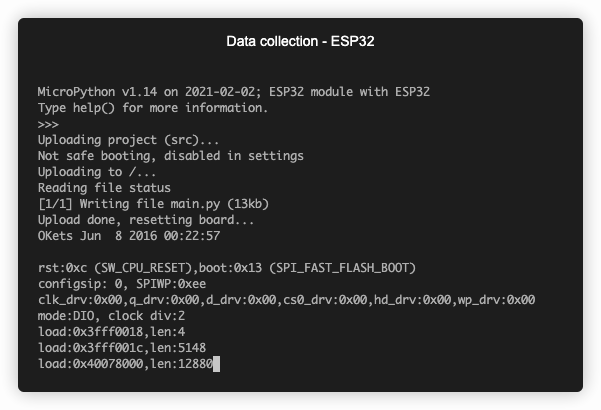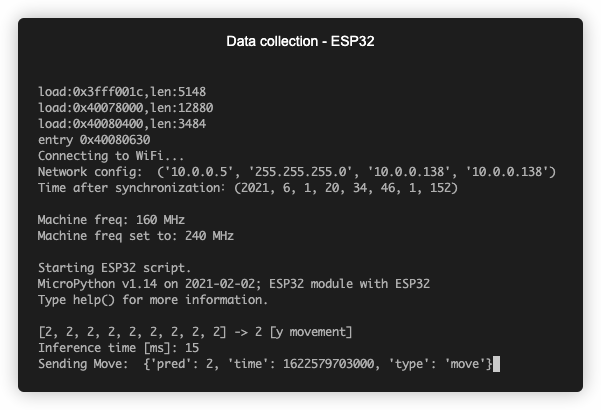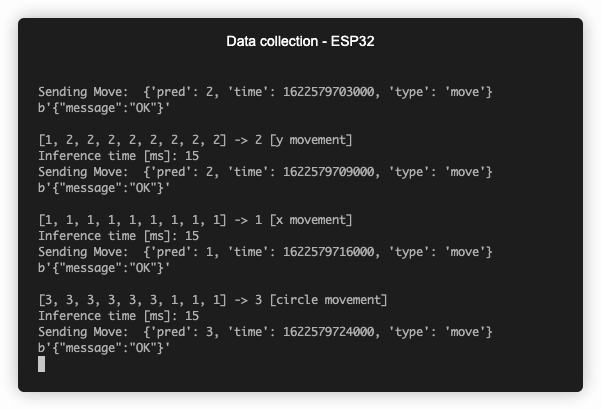
Inference on ESP32
Future tweaks
I am already thinking how to tweak this project to achieve faster classification, more accurate results. Here's a couple of ideas I am thinking about:
- Improve model evaluation by labelling validation data or by designing better evaluation methods.
- Implement feature extraction in addition to time-series data to (possibly) achieve better inference results.
- Implement async writes to DB on backend. Shorter response time -> shorter blocking. *MPY requests module implementation does not yet support async.
- Replace HTTP requests (does not support async) with MQTT (supports async)
- Implement digital signal processing methods to smooth out signals.
- Improve data handling - memory allocation errors with 900 data points.
- Compare evaluation results to dedicated time-series models and neural networks.
Summary
To conclude - it is clearly possible to classify gestures on an ESP32 microcontroller using standard machine learning algorithms, and MicroPython but some corners need to be cut. Among others, time-series data must be tabularized, highest possible sampling rate is 100Hz (with current setup).
Future scope
While working on this project I found many interesting sources and projects implementing TinyML with Tensorflow Lite Micro, DeepC and similar. Next, I'd like to explore implement gesture classification using neural networks to compare the results between standard ML and DL.
Reach out if you have any questions or suggestions. 👏
Repos
Note: Code is work-in-progress.
